
|


Why another memory manager? Because to this day memory management can be subdivided in two categories:
And we will see below that neither of them is objective enough to cover all use cases.
In one hand the garbage collectors do not offer deterministic destruction of the objects which creates this unpredictable behavior that is unpleasant to see on a front end user-interface experience for example.
On the other hand the reference counting is deterministic but do not offer any way to detect cyclic references. So no clean solution exists to resolve this problem up until now.
We will see below a description of the aforementionned items and the solution proposed by this library to solve this.
garbage collection is a technique where memory blocks are collected and later deallocated when they are found to be unreferenced by any other object.
Garbage collection is used by many popular languages including:
Garbage Collector Advantages are:
Garbage Collector Disadvantage:
An example of its usage is demonstrated here with the C/C++ implementation of the popular Hans Boehm garbage collector:
#include <gc.h> int main() { int * p = (int *) GC_MALLOC(sizeof(int) * 100); // Allocate an array of 100 integers. return 0; } // non-deterministic deallocation of the array.
Unfortunately this technique simply postpones the deallocation of the unreferenced objects to later freeze the entire application, on a single CPU system, and to collect them using various tracing algorithms. This may be unacceptable for real-time applications or device driver implementation, for example.
For solar or battery-powered devices, the power consumed by garbage collection might also be significant.
Reference counting is a different approach where objects pointed to are aware of the number of times they are referenced.
This means a counter within the object is incremented or decremented according to the number of smart pointers that are referencing or dereferencing it.
For example, using boost::shared_ptr (or the std:: version):
#include <boost/smart_ptr/shared_ptr.hpp> #include <boost/smart_ptr/weak_ptr.hpp> using boost::shared_ptr; using boost::weak_ptr; #include <boost/make_shared.hpp> using boost::make_shared;
struct S { shared_ptr<S> q; ~S() { // std::cout << "~S()" << std::endl; // ~S() output when S is destructed. } };
shared_ptr<int> p = make_shared<int>(11); shared_ptr<int> q = p; p.reset(); std::cout << *q << std::endl; // Outputs 11.
The main drawback is a lost in performance as compared to garbage collection because of the extra time required to manage the counter every time the pointer is reassigned or dereferenced.
Reference counting can also leave a group of blocks of memory referencing each other (called "cyclic") unnoticed and therefore never freed by the application.
A cyclic set is shown here:
struct S { shared_ptr<S> q; ~S() { // std::cout << "~S()" << std::endl; // ~S() output when S is destructed. } };
shared_ptr<S> p = make_shared<S>(); p->q = p; // Create a cycle. p.reset(); // Detach from the cycle.
The above example will never execute the call of the destructor of struct A
because the cycle will never get deallocated. This is because the number of
references will never reach 0.
A way to solve this problem is to isolate the location of the cycle, which
is this case is already known, and use a weak_ptr
to break the cycle:
struct W { weak_ptr<W> q; ~W() { // std::cout << "~W()" << std::endl; // ~W() output when W is destructed. } };
shared_ptr<W> p = make_shared<W>(); p->q = p; // Create a cycle. p.reset(); // Detach from the cycle.
The main drawback of this approach is the need to explicitly find the cycle
to later alter the code with respective weak_ptrs.
The solution we present here to solve these problems is called Root Pointer which is basically a "container-oriented" memory manager on top of reference counting that is also able to detect outright unreferenced cyclic blocks of memory. It is deterministic so the destruction of the objects is predictable.
The purpose of Root Pointer is to offer a predictable solution like the reference
counting and to provide a means to manage groups of related memory allocations
using a root_ptr. Each related
memory allocation is a node_ptr created from, or attached to, one root_ptr. Because node_ptrs
are grouped and owned by a root_ptr,
they are destroyed, as a group, when the corresponding root_ptr
is destroyed, regardless of cycles.
Furthermore it is not requiring a bigger memory usage per pointer (2 *
sizeof(void *)) for
its associated node_ptr and
(2 * sizeof(void *) +
sizeof(node_proxy))
for root_ptr itself, given
its ability to detect cyclic blocks of memory.
For example:
#include <iostream> #include <boost/smart_ptr/root_ptr.hpp> using namespace std; using namespace boost; struct A { node_ptr<A> p; A(node_proxy const & x) : p(x) { } ~A() { cout << "~A()" << endl; // will get called } }; int main() { root_ptr<A> x; x = make_root<A>(x); x->p = x; return 0; } // deterministic destruction
We can see in the above example that there is no need to manually find the location of the cycle.
When should it be used? It is mostly helpful in the following cases:
Will there be a performance loss? According to the following graphic, the answer is no if we compare it to a shared_ptr:
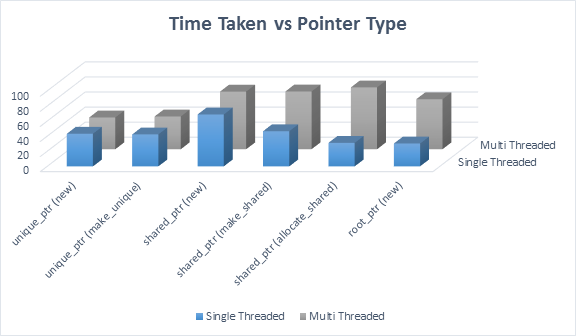
In other words, there is no need to any other smart pointer if Root Pointer is used properly for new code.